 Real-time streaming JOINs don’t have to be complicated to code, and they don’t
have to be the bottleneck in your system. In AMPS, we designed our JOINs from
the ground up to be easy to use and highly performant. AMPS is unique in that
it provides a hybrid approach to data movement and storage. Thanks to AMPS’
revolutionary State of the World cache (SOW), we are able to provide unbounded,
windowless JOIN support in real-time! Companies rely on AMPS every day to
process data at incomparable speeds, but now with JOIN support, we have
eliminated the need for latency-adding (and pricey) secondary CEP systems.
Joining data upstream, relieves expensive downstream work, thus lowering
overall latency.
Real-time streaming JOINs don’t have to be complicated to code, and they don’t
have to be the bottleneck in your system. In AMPS, we designed our JOINs from
the ground up to be easy to use and highly performant. AMPS is unique in that
it provides a hybrid approach to data movement and storage. Thanks to AMPS’
revolutionary State of the World cache (SOW), we are able to provide unbounded,
windowless JOIN support in real-time! Companies rely on AMPS every day to
process data at incomparable speeds, but now with JOIN support, we have
eliminated the need for latency-adding (and pricey) secondary CEP systems.
Joining data upstream, relieves expensive downstream work, thus lowering
overall latency.
Decisions due to Embellishment
In real-time systems, the very mention of the word “JOIN” brings to mind one thing - increased latency. JOINs in the database world are a necessity, whereas in the streaming world, they should be considered a luxury. All of this super-fast streaming data comes at a typically unacknowledged cost - the data still needs to be consumed. Streaming data must be embellished, interpreted, and applied to some business process. Whether that process is manual or assumed by other software system, it is added to the end-to-end latency.
All this extra data has a remarkable impact to performance, which is unacceptable in any serious venue. Then why would one even consider the use of a JOIN when streaming real-time data? As it turns out, you can get by perfectly fine without joining disparate entities. That is, until the data needs to be ingested into a decision-making process. To obtain a clear picture on what we mean, let’s begin with a seemingly simple example.
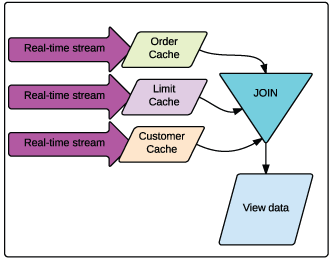
Publisher/subscriber systems process Orders in real-time, whereas the Customers and Limits are not processed with the orders, but rather stored in a historical database. To extract meaningful insight out of the orders, they must be combined with the customer and limit data. There are many ways to do this, but we tend to see complex event processing (CEP) systems assuming this role. Traditional complex event processors are great for such aggregation, but they lose their luster when you decouple them from the ultra-fast streaming engines.

Even the fastest CEP engines still need to ingest data from the publisher via an adapter and transform that stream into workable data.
An introduction to windowless real-time, streaming joins.
Traditional CEP systems require bounded JOIN support; this means that you typically must provide a time-based window in which to exercise your JOIN statement. In CEP systems, the streaming JOIN operation is temporal, meaning that disparate streams of events must have overlapping lifetimes. It is not to be confused with the joining of historical and embellishment data, which is typically stored in a separate database system. The streaming JOIN operation of traditional CEP systems are conceptually different than historical database systems, where a JOIN is evaluated over the entirety of your source data. The reason why these systems differ in their support of JOINs is due to how they fundamentally access data. CEP systems work on “streams” of data, whereas databases work on stores of data. Due to AMPS’ revolutionary State of the World cache (SOW), we are able to provide a hybrid approach – one where you can JOIN data streams with historical data in real-time.
But what does it mean when we say “real-time?” Well, CEP systems, while operating on streams of data, tend to operate over specified windows of time. Whether utilizing sliding windows, hopping windows, or some variation of the two, the entirety of the window’s specified time must elapse before a calculation can occur. The “windowed real-time” operation of the CEP JOIN is now delayed by the elapsed time of that window. AMPS operates in “real-time” in that we JOIN data as it arrives, rather than waiting for some expiration. Additionally, as mentioned above, your streaming data can be joined with your historical data in the same real-time latency.
Let’s now examine how we would implement the previous example in AMPS. The differences should be immediately clear; there are no adapters, there are no delayed windows, and there is only one system from which to aggregate data – this is AMPS! All of your data, whether real-time, historical, or embelishment is treated exactly the same. Not only does this greatly simplify development and adminstration due to its conceptually clean implementation, but it also allows for slowly updating sources (Limits and Customers).

./spark subscribe -type nvfix -server localhost:9003 -topic CUSTOMER_TOTAL_OF_LIMIT
Back to the Future
In the previous example, we saw how we can enrich the order data with its customer and their daily limits. But what if we would like to examine a customer’s activity over the past year? In your CEP system, you probably need to create another input adapter to your historical data store. If you would like to combine the customer’s history with their current activity, you’ll need to create a CEP stream that JOINs the two data inputs and figure out some way to negate the overlapping data. At this point, you have the following:
- JOINs within your current activity stream,
- JOINs within your historical activity stream,
- A JOIN to link your current and historical activity streams into a single stream,
- A expensive de-duplicating operation,
- A window, expressing your current activity stream

Let’s compare this with how you would accomplish the same thing in AMPS. In AMPS, you already have the query that JOINs orders, customers, and their daily limits. Since the SOW stores current and past data, we only need to query the SOW for the old Orders and subscribe to the new Orders. We do this through the use of AMPS’ unique sow_and_subscribe command:
./spark sow_and_subscribe -type nvfix -server localhost:9003 -topic CUSTOMER_TOTAL_OF_LIMIT
Notice that I did not include a new architectural diagram. The architecture here is the same as it was in Figure 3. That’s because, unlike a traditional CEP, AMPS doesn’t require a hodgepodge of disjoint systems to accomplish conceptually simple tasks. Its power and simplicity derive from a smart, robust, and extensible architecture - one that puts developers first!
Try it yourself!
In this article, I have made some grand statements on our performance, comparisons with other products, and our ease of use. If you’re intrigued by them, whether they spark your interest or you simply disagree, we invite you to download a free evaluation and try it yourself!