 - Flume, 1965, Werner Lenggenhager, State Library Photograph Collection, 1851-1990, Washington State Archives, Digital Archives, http://www.digitalarchives.wa.gov, April 3 2017.")
60East customers often integrate their AMPS deployments with the wider ecosystem of cloud storage providers, text search and analysis platforms, and the Apache ecosystem of big data tools such as Spark and Hadoop. One common integration request is the ability to pull an AMPS message stream directly into Apache Flume so that messages can be easily routed to HBASE, Hive, Amazon S3 or Elastic Search for further analysis or processing.
AMPS provides sophisticated message processing capabilities that complement Flume in an end-to-end system. AMPS inline enrichment and powerful analytics and aggregation (including aggregation of disparate message formats) make it easy to provide processed and enriched data to the destination system. AMPS also provides high-performance content filtering to precisely identify messages of interest, reducing network overhead, storage requirements, and processing time for the destination system. Even better, AMPS provides conflation, paced replay, and resumable subscriptions so that the destination system is never overwhelmed with the volume of incoming messages, and can be populated even in the case of a network outage, planned maintenance, or a failure in a component.
Today, we’re making this integration easier by releasing a custom AMPS source for Apache Flume NG.
Apache Flume NG
To paraphrase Apache’s project page, Apache Flume NG (simply “Flume” or “Apache Flume” below) is a distributed and reliable service for collecting and aggregating large amounts of data. The “data” routed through Flume can be anything that is adapted to fit Flume’s Event abstraction, which is the basic data unit in Flume. Use cases for Flume include social media, trades/executions, and IoT sensor/geo-location data, as well as logging events.
Flume is typically run on one or more machines, with each Flume Java process executing a Flume Agent. A Flume Agent is configured to have one or more “sources” that pull in data from various systems. Sources write data to one or more configured “channels”, which usually provide transactional integrity (depending on type). Channels can be configured to have one or more “sinks” that drain their channel of data and write it to some destination system.
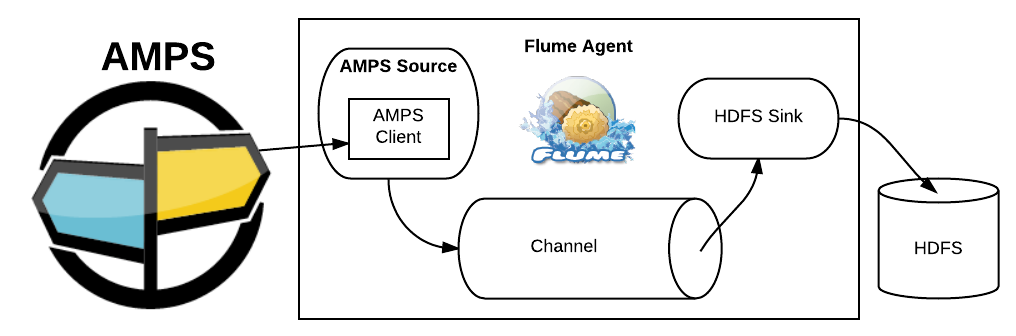
Flume comes with a variety of built-in source types for importing data from various data sources, such as a generic NetCat source for setting up a network listener socket, to more specialized sources for pulling in data from Syslogs, JMS, Twitter; or in specific data formats such as Avro or Thrift.
Flume channels come in a variety of types as well, from the simple and fast (but non-transactional and non-durable) Memory Channel, to slower reliable options that provide transactional guarantees such as a File Channel or JDBC Channel (for committing to any relational database that provides a JDBC driver).
Similar to sources and channels, Flume also provides various built-in sink types. These include sinks for writing to the Flume log file (Logger Sink), for writing events to a rolling series of files in a specified filesystem directory (File Roll Sink), and by far its most popular sink, the HDFS Sink, for writing events to the Hadoop Filesystem for downstream batch processing by big data systems such as Apache Hadoop or Apache Spark.
Flume also provides the means for third parties to implement their own custom implementations of sources, channels, and sinks, to suit specific needs. For example, connecting to AMPS.
The AMPS Flume Source
Flume’s ability to be extended with custom implementations of its components is where the subject of this blog comes in. 60East has released a Flume source capable of pulling in messages from an AMPS subscription and committing those messages to whatever channels the source is attached to in the Flume configuration.
The custom AMPS source implements a “pollable” Flume source by sub-classing org.apache.flume.source.AbstractPollableSource. This allows the AMPS client created inside the source to read messages from an AMPS subscription and batch them up, committing them to all the channels attached to the source whenever Flume polls the source. This approach is far more desirable from a performance perspective than an event-driven source that commits each message as the message arrives: that approach incurs channel transaction costs on a per message basis.
Getting Started
To get started you will need at least a Java 7 JDK, Maven 3.3, and Apache Flume NG 1.7.0. First clone the AMPS Flume source repository from GitHub:
git clone git@github.com:60East/amps-integration-apache-flume.git amps-flumeFollow the build and installation instructions in the README.md file located in the cloned directory (also available under https://github.com/60East/amps-integration-apache-flume ). This will walk you through building the AMPS Flume source JAR and how to install it as a plugin in your Apache Flume installation.
Once you have the AMPS source installed as a plugin, you can use it within your Flume configuration. Below is an example configuration for an AMPS Flume source:
# Example config for an AMPS Flume Source
agent.sources.amps.type = com.crankuptheamps.flume.AMPSFlumeSource
agent.sources.amps.clientFactoryClass = com.crankuptheamps.flume.AMPSBasicClientFunction
agent.sources.amps.clientName = FlumeClient
agent.sources.amps.bookmarkLog =
# For one AMPS server, you can just specify "uri".
# For multiple HA AMPS servers, specify multiple URIs with an index number.
agent.sources.amps.uri1 = tcp://server1:9007/amps/json
agent.sources.amps.uri2 = tcp://server2:9007/amps/json
agent.sources.amps.command = sow_and_subscribe
agent.sources.amps.topic = Orders
agent.sources.amps.filter = /symbol IN ('IBM', 'MSFT')
agent.sources.amps.options = projection=[/symbol,avg(/price) as /avg_price,\
avg(/price*/qty) as /avg_total],grouping=[/symbol],conflation=1s
agent.sources.amps.subscriptionId = Sub-100
agent.sources.amps.maxBuffers = 10
# maxBatch must be <= the smallest transactionCapacity of all channels
# configured on the source.
agent.sources.amps.maxBatch = 1000
agent.sources.amps.pruneTimeThreshold = 300000Here we’re configuring a Flume agent called agent, as can be seen above in the configuration key prefix. Under agent’s sources we have configured our source to be called amps. The type of any AMPS source must be the class com.crankuptheamps.flume.AMPSFlumeSource. This is the class from our Apache Flume integration repository that implements our custom AMPS source.
Client Settings
The clientFactoryClass configuration key is optional. By default it will use the built-in implementation, com.crankuptheamps.flume.AMPSBasicClientFunction, which will make use of the clientName, bookmarkLog, and uri[n] configuration keys to create an AMPS HAClient instance. If you have need of customizing the AMPS client creation process, such as to use a custom AMPS authenticator, a custom server chooser, or even a custom HAClient sub-class, you can create your own AMPS client factory by implementing the SerializableFunction<Properties, Client> interface from the AMPS 5.2.0.0 Java client. See the source code of com.crankuptheamps.flume.AMPSBasicClientFunction for an example of this. You would then need to package your client factory class inside AMPSFlumeSource-1.0.0-SNAPSHOT.jar, or in your own JAR that is placed in the $FLUME_HOME/AMPSFlume/libext/ directory. Then just specify your client factory’s fully qualified class name as the value of the clientFactoryClass configuration key.
The clientName configuration key is required and like any AMPS client name, it must be unique across all AMPS clients connecting to a high availability (HA) cluster.
The bookmarkLog configuration key is used to specify the absolute or relative path to the bookmark store log file. This configuration key is optional. If this is specified, the source will create a bookmark subscription for reliability purposes. The default client factory implementation will always use a LoggedBookmarkStore implementation on the client it creates when this key is specified.
The uri configuration key is required. It is used to specify one or more AMPS server transport URIs that you would like the AMPS client to connect to. If you only have a single AMPS server you want to connect to, the key may be specified as either uri or uri1. If you want to specify multiple AMPS servers in an HA cluster, each transport URI should be specified with an index number, starting with “1” and having no gaps. For example, uri1, uri2, and uri3 for three URIs.
Subscription Settings
The command configuration key is optional. If not specified its value defaults to subscribe for an ordinary subscription, though you could also specify values such as delta_subscribe, sow_and_subscribe or sow_and_delta_subscribe. In our example we are using the sow_and_subscribe command to query the State of the World (SOW) database topic and then subscribe to it for future updates.
The topic configuration key is required. This is the topic used in the AMPS subscription. Like any AMPS subscription, this may be a valid regular expression to allow subscribing to multiple topics.
The filter configuration key is optional. This is the filter expression used on the AMPS subscription. Our example here will filter incoming messages to just those with /symbol values of IBM or MSFT.
The options configuration key is optional. These are the options to be used on the AMPS subscription. In our example here we are using the new AMP 5.2 aggregated subscription feature to group the data by /symbol and project calculated view fields. We are also using a conflation interval of 1 second to collect all updates to the topic within a second and only send our Flume client at most one update per a second.
The subscriptionId configuration key is used to specify the subscription Id for a bookmark subscription, so when Flume is restarted it can recover from the bookmark log and continue the subscription where it left off. This should be unique amongst all subscriptions in the application. If the bookmarkLog configuration key is specified, then this is required, otherwise it’s optional.
Tuning Settings
The maxBuffers and maxBatch configuration keys control the batching of AMPS messages that are committed to the channel(s). They are both optional and have default values of 10 and 1000 respectively. These can be tuned to trade-off performance verses memory usage of the AMPS source. The maxBuffers key determines the maximum number of AMPS message buffers the source will queue up in memory before pausing to let Flume sinks catch up in draining attached channels.
The maxBatch configuration key is the maximum number of AMPS messages allowed inside a message buffer. This is the maximum batch size that will be committed to all attached Flume channels. As such, this value MUST be less than or equal to the transactionCapacity of every channel attached to the source, or you will always get channel commit errors (ChannelException) in the Flume log and no messages will ever reach attached channels or sinks.
If you multiply maxBuffers and maxBatch you will get the maximum number of AMPS messages held in source memory waiting to be committed to all attached channels. If sinks don’t drain attached channels fast enough, this limit will be reached and you will see this warning in the Flume log:
Pausing AMPS message processing to let Flume source polling catch-up.
Consider increasing maxBuffers; or maxBatch and the transaction
capacity of your Flume channel(s).If the source uses a bookmark subscription, the AMPS Flume source doesn’t discard any AMPS message in the bookmark store until it has been committed to all channels attached to the source. So if a Flume agent suddenly goes down with thousands of messages batched in memory, upon restart the subscription will be recovered from the bookmark log and all messages that haven’t been marked as discarded will be redelivered to the AMPS source. For each batch, there is a small window between the time Flume indicates that attached channels are successfully committed and when bookmark store discards take place. If an outage occurs in this window, then all or some of the committed messages will be redelivered upon restart (though messages will always be in the proper order for a given publisher and there will be no gaps). This means that the AMPS Flume source provides at-least-once delivery semantics for bookmark subscriptions.
The pruneTimeThreshold configuration key is optional and has a default value of 300,000 milliseconds (5 minutes). This key determines the minimum amount of time that must elapse before the client’s LoggedBookmarkStore will be pruned of obsolete entries. The elapsed time is measured from the source’s start-up time or from when the last prune operation was performed. For debugging and testing purposes, this value can be set to zero to turn off all pruning (NOT recommended for general production use). The LoggedBookmarkStore will also be pruned upon normal Flume shutdown, unless this value is zero. If a custom client factory installs another bookmark store implementation on the client, then this configuration key has no effect.
Cranking It Up
Included in the project repository is a working example that shows off the powerful new aggregated subscription feature of AMPS 5.2 (for more info see our blog post on aggregated subscriptions).
Go to your cloned GitHub repository directory. Copy the example Flume configuration file to your Flume 1.7 installation:
cp src/test/resources/flume-conf.properties $FLUME_HOME/conf/Be sure to rename the file if you already have a config file by the same name.
Next, start an AMPS 5.2 server instance with the included AMPS config file at: src/test/resources/amps-config.xml
Create a directory at /tmp/amps-flume/ to hold the event output of Flume:
mkdir /tmp/amps-flume/Now start Flume from your $FLUME_HOME directory:
bin/flume-ng agent -Xmx512m -c conf/ -f conf/flume-conf.properties -n agent -Dflume.root.logger=INFO,consoleLastly, publish the example JSON messages to the Orders topic using the AMPS spark utility:
spark publish -server localhost:9007 -topic Orders -rate 1 -file src/test/resources/messages.jsonNotice that we are publishing at a rate of 1 message per a second, so that in the output we can see the aggregate fields change over time as updates arrive.
These are the 15 messages we are publishing:
{"order_key":1, "symbol":"MSFT", "price":62.15, "qty":100}
{"order_key":2, "symbol":"MSFT", "price":62.22, "qty":110}
{"order_key":3, "symbol":"IBM", "price":180.40, "qty":125}
{"order_key":4, "symbol":"FIZZ", "price":61.77, "qty":4000}
{"order_key":5, "symbol":"YUM", "price":64.07, "qty":123}
{"order_key":6, "symbol":"IBM", "price":181.02, "qty":200}
{"order_key":7, "symbol":"FIZZ", "price":61.45, "qty":2300}
{"order_key":8, "symbol":"MSFT", "price":62.52, "qty":1000}
{"order_key":9, "symbol":"IBM", "price":180.90, "qty":750}
{"order_key":10, "symbol":"MSFT", "price":62.45, "qty":900}
{"order_key":11, "symbol":"YUM", "price":64.11, "qty":460}
{"order_key":12, "symbol":"IBM", "price":180.85, "qty":150}
{"order_key":13, "symbol":"FIZZ", "price":61.50, "qty":600}
{"order_key":14, "symbol":"MSFT", "price":62.70, "qty":1200}
{"order_key":15, "symbol":"IBM", "price":180.95, "qty":480}After about 15 seconds (due to our 1 second rate of publishing and our 1 second conflation interval) our aggregated subscription view of the data gives us the following results under /tmp/amps-flume/:
{"symbol":"MSFT","avg_price":62.15,"avg_total":6215.0}
{"symbol":"MSFT","avg_price":62.185,"avg_total":6529.6}
{"symbol":"IBM","avg_price":180.4,"avg_total":22550.0}
{"symbol":"IBM","avg_price":180.71,"avg_total":29377.0}
{"symbol":"MSFT","avg_price":62.2966666666667,"avg_total":25193.0666666667}
{"symbol":"IBM","avg_price":180.773333333333,"avg_total":64809.6666666667}
{"symbol":"MSFT","avg_price":62.335,"avg_total":32946.05}
{"symbol":"IBM","avg_price":180.7925,"avg_total":55389.125}
{"symbol":"MSFT","avg_price":62.408,"avg_total":41404.84}
{"symbol":"IBM","avg_price":180.824,"avg_total":61682.5}For cases where the entire raw message stream is desired at maximum throughput, you would use a subscribe command and wouldn’t specify options such as projection, grouping, or conflation. For reliability and restart recovery, you would need to then specify the bookmarkLog configuration key to use a bookmark subscription.
Conclusion
Importing an AMPS message stream into Flume used to require intermediate steps and third party software. Now integrating AMPS with Apache Flume has never been easier. The new AMPS Flume source allows you to plug an AMPS subscription directly into a Flume flow.
How do you plan to use the Flume integration? Would you like to see AMPS connected to other software stacks – either as a sink or source? Let us know in the comments!