
In some applications, unique identifiers for objects change through the object’s lifetime. It can be difficult to decide how to model this in systems where an identifier is necessary, such as topics in the AMPS State-of-the-World (SOW).
A prime example of this problem is in FIX Order ID Chaining. The FIX specification allows systems to declare that a previous Order is canceled and that a new Order, with a new ID, replaces it. A system does this by using the /41 or /OrigClOrdID field of the message. Applications frequently want to model this replacement order as the same Order object as the previous message. In this case, though, there is no shared identifier in a common field that exists across the “chain” of orders, so there’s no common field that can be used as a Key:
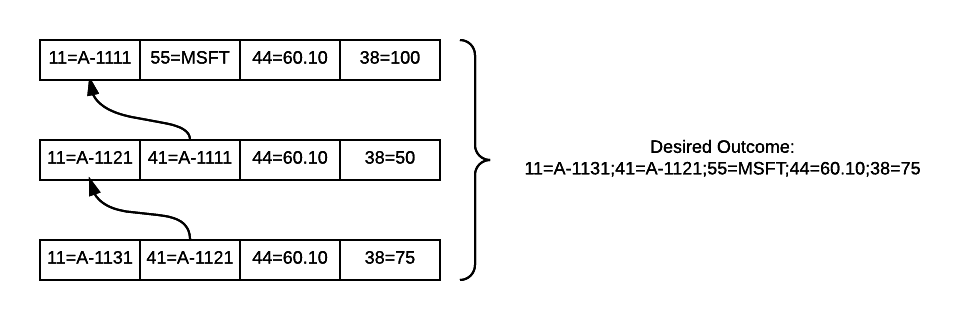
In the diagram, three messages representing one Order are seen, but neither the /11 or /41 fields are suitable for a unique ID. For any given combination of /41 or /11 present in an incoming message, previously seen values for those identifiers must be consulted to determine if the incoming message is an update to a previous record, or if the message constitutes a new Order.
Introducing AMPS ID Chaining
AMPS 5.2 provides new functionality which supports correctly identifying messages that follow this chaining pattern. The functionality is called the ID Chaining module, and is configured in your SOW topic configuration. Here’s an example:
<Modules>
<Module>
<Name>libamps-id-chaining-key-generator</Name>
<Library>libamps_id_chaining_key_generator.so</Library>
</Module>
</Modules>
...
<SOW>
<Topic>
<Name>Orders</Name>
<FileName>./sow/%n.sow</FileName>
<MessageType>nvfix</MessageType>
<KeyGenerator>
<Module>libamps-id-chaining-key-generator</Module>
<Options>
<Primary>/11</Primary>
<Secondary>/41</Secondary>
<FileName>./sow/order.chaining.data</FileName>
</Options>
</KeyGenerator>
</Topic>
</SOW>Let’s dissect this configuration file a bit.
The first section, Modules, loads an optional module that ships with AMPS called libamps_id_chaining_key_generator.so. This module is now available for use as we declare SOW topics.
Later in the configuration, we declare a SOW topic called Orders of message type nvfix. Unlike most SOW topics, we never specify a <Key>; instead, we specify a KeyGenerator element referring to the libamps-id-chaining-key-generator module we loaded above. This results in AMPS invoking the ID Chaining module to create a SOW key for each incoming record.
We pass Options to the ID Chaining module to configure it for our data. The Primary and Secondary options are used to indicate the message fields which serve as the current/primary ID, and the previous or secondary ID. If you’re configuring the module for use with standard FIX data, these will most typically be set to /11 and /41, but they may be set to any fields you’d like. The FileName option specifies a file you want the module to store its state in. The module will read this file on startup and keep it updated with the data it needs to preserve the linkage between every valid identifier for each chain.
See It In Action
With this configuration, let’s publish some sample data and see what happens. Here’s our sample data set:
$ cat -v orders.nvfix
11=A-1111^A55=MSFT^A44=60.10^A38=100^A
11=A-1121^A41=A-1111^A44=60.10^A38=50^A
11=A-1131^A41=A-1121^A44=60.10^A38=75^A
11=B-1111^A55=IBM^A44=120.01^A38=100^A
11=B-1121^A41=B-1111^A44=120.01^A38=50^A
11=B-1131^A41=B-1111^A44=120.01^A38=75^ANotice we have two order chains present; one identical to the example in the first diagram (the MSFT order chain). The second order chain (IBM) has a significant difference: the third publish refers to the first ID used in that chain, B-1111. Let’s publish this data and see how AMPS resolves these ID chains:
$ ~/spark publish -delta -server localhost:9007 -topic Orders -type nvfix -file orders.nvfix
total messages published: 6 (3000.00/s)
$ ~/spark sow -server localhost:9007 -type nvfix -topic Orders | cat -v
11=A-1131^A41=A-1121^A44=60.10^A38=75^A55=MSFT^A
11=B-1131^A41=B-1111^A44=120.01^A38=75^A55=IBM^A
Total messages received: 2 (Infinity/s)As expected, AMPS ID Chaining resolved these 6 messages into two distinct Orders. Note that even though we used an older ID (B-1111) in the 3rd publish on the IBM chain, AMPS was still able to resolve this publish to the correct chain. This is because AMPS ID Chaining tracks every distinct ID ever used in the chain, not just the most recent. Doing so frees systems from being concerned that an older order ID might still be used by upstream systems.
Failure Detection
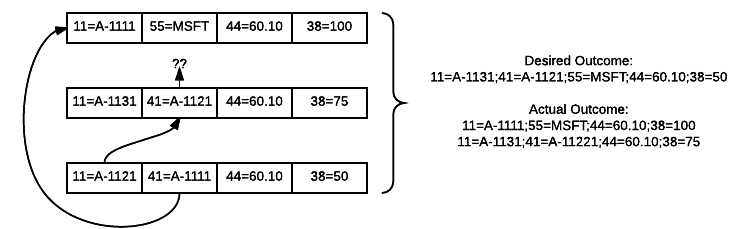
AMPS ID chaining requires that two distinct chains are never resolved together by a future message. For example, this order of publishes cannot resolve to a single message, because the 3rd publish attempts to resolve two existing order ID chains into one:
If publishers cannot be prevented from publishing data which creates this scenario, the ID Chaining module includes a Validation configuration option which detects ID Chaining sequencing errors. This option requires extra space and processing time, but can be very helpful in tracking down publisher errors. To enable this option, update the configuration with an entry like the following:
<KeyGenerator>
<Module>libamps-id-chaining-key-generator</Module>
<Options>
<Primary>/11</Primary>
<Secondary>/41</Secondary>
<FileName>order.chaining.data</FileName>
<Validation>true</Validation>
</Options>
</KeyGenerator>When a publisher publishes data with a sequencing error that AMPS detects, errors are emitted to the AMPS log and the message is rejected:
2017-03-07T15:01:53.5953200-08:00 [32] warning: 29-0104 Sequencing error: An attempt to map id [A-1121] to SOW key 15073404310751987725 failed, because it was already mapped to SOW key 12015654067891347767. This indicates a sequencing error in upstream publishers.
2017-03-07T15:01:53.5953220-08:00 [32] error: 02-0040 client[my-publisher] published a message which could not be processed by the SOW KeyGenerator:
topic = 'Orders'
client seq = 0
data = [11=A-1121^A41=A-1111^A44=60.10^A38=50^A]Conclusion
Systems that process FIX orders are often faced with the need to track “chains” of order IDs that change through time, but this problem isn’t confined to FIX orders. Many systems are faced with challenges of identifiers that are not constant. AMPS ID Chaining provides an important tool when working with data that lacks a consistent unique ID per object. For more information on using this feature, consult the User Guide