
The Advanced Message Processing System (AMPS) from 60East Technologies is used in production for thousands of enterprise messaging applications. These applications use AMPS because they have the most demanding throughput and latency requirements for publish/subscribe messaging. These applications also take advantage of the AMPS durable message storage, historical replay and audit, global replication and high availability, sophisticated aggregation and analytics, and more. The 5.0 release of AMPS adds durable message queues, built on the proven AMPS engine for the highest levels of reliability and performance.
To illustrate the performance of AMPS queues, our engineers ran a head-to-head comparison against RabbitMQ, the most popular message queueing product in use today. This document captures the performance testing results and compares features and functionality. While AMPS supports multi-messaging paradigms and provides extensive capabilities beyond message queueing, this paper focuses on the features of AMPS that are most relevant to solutions benefiting from message queueing. A majority of the AMPS user base deploys AMPS into enterprises that cannot tolerate message loss or low performance. AMPS Queues are durable by default and are able to achieve 40x the throughput of RabbitMQ with better durability and message delivery guarantees.
AMPS Queues are durable by default and are able to achieve 40x the throughput of RabbitMQ with better durability and message delivery guarantees.
Performance Comparison
In this comparison, durable queues were used in both AMPS and RabbitMQ. The AMPS test used the AMPS C++ client library, and the RabbitMQ test used the alanxz/rabbitmq-c library. For both products, the consumers were set to acknowledge consumption in batches of 80 messages. For RabbitMQ, 60East set the prefetch count for each subscriber to 100 messages in an attempt to achieve higher performance and reduce the time waiting for new messages to arrive. For AMPS, the maximum backlog of the subscription was set to 100 messages and the proportional distribution method was used in order to optimize for subscriber efficiency. This approach is the most compute-intensive distribution method for the server.
Test results were run in the 60East Engineering Lab. Both tests were run on the same system, a Supermicro SYS 1028U TNR4T+ with 2 Intel Xeon E5-2690 v3 processors (@ 12 cores each) and 128GB of memory. All tests were run over the loopback interface, with both publishers and subscribers on the same system.
Because AMPS is able to completely saturate the storage on most systems, our engineers ran the test persisting the queues to two different storage devices. The first test used a mid-range, enterprise-class, 7200RPM spinning drive for the queue persistence.
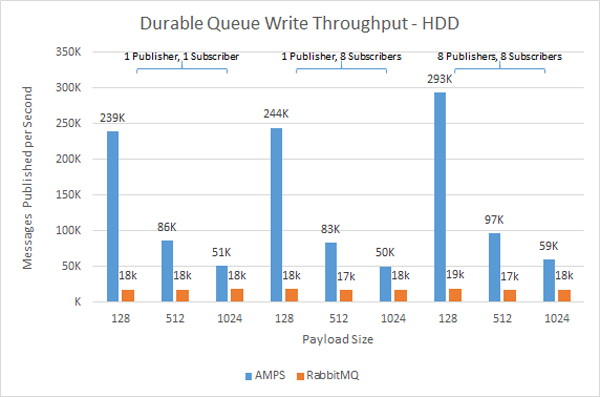
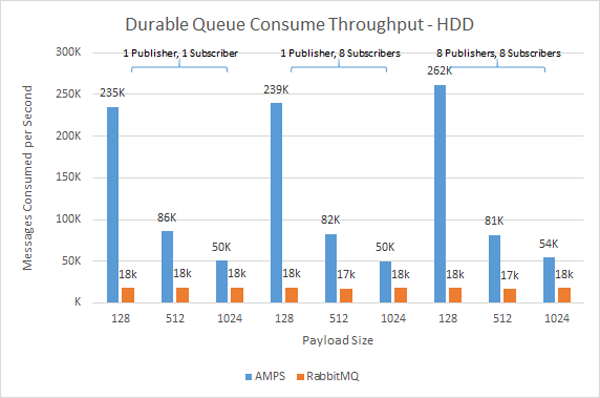
For all message sizes, AMPS consistently outperforms RabbitMQ by factors ranging from 2X - 15X better for both publishers and subscribers. More interesting than that, though, is that while AMPS performs better with smaller messages – as would be expected, since the storage device can handle more messages in the same amount of I/O bandwidth – RabbitMQ provides consistent performance regardless of the message size, which indicates that the performance is a result of the RabbitMQ implementation rather than I/O constraints.
Most production installations of AMPS are for applications that require the highest levels of throughput and lowest levels of latency. To test performance under these conditions, our engineers moved the persistence to an Intel DC P3700 NVMe PCIe solid state storage device.
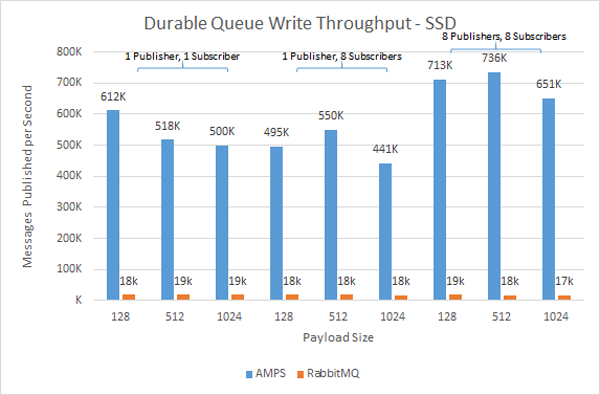
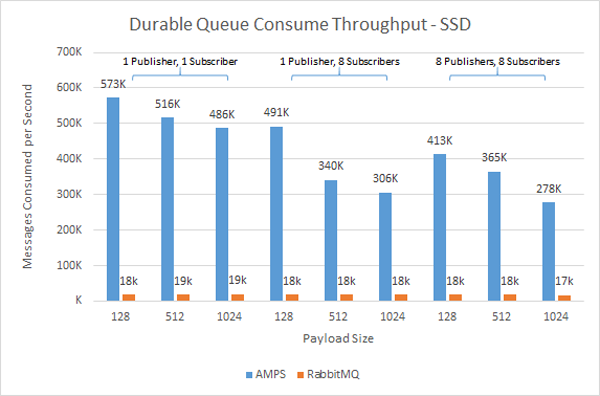
As in the hard disk scenario, AMPS performed significantly better, with results 24x - 40x better for publishers and 16x - 30x better for subscribers. The most surprising results were that RabbitMQ seemed to gain little or no performance benefit from higher-bandwidth I/O. Notice that, for all tests, RabbitMQ provides consistent performance, regardless of the amount of traffic being delivered to the drive. AMPS, in contrast, fully uses the I/O capacity of the drive, and scales with the usage of that capacity.
There are two notable differences in performance. The first is the difference in magnitude. AMPS was faster in testing across the board. The second difference is the difference in device scalability. AMPS performance dramatically improved with a faster device, while RabbitMQ’s low performance remained constant, providing no material benefit from the upgraded storage device.
RabbitMQ's low performance remained constant, providing no material benefit from the upgraded storage device.
This behavior is a result of the difference in persistence guarantees between the products. AMPS fully persists messages before providing them to subscribers, which means that AMPS performance scales proportional to the bandwidth of the storage device. In contrast, RabbitMQ uses a strategy that batches calls to fsync [1] – which means that that RabbitMQ does not depend on I/O throughput and has constant performance regardless of the amount of bandwidth made available.
This explains the difference in scalability between RabbitMQ and AMPS. But that’s not the most striking result in the research.
Why are the differences in performance so large?
What’s Going On?
The difference is not a result of the test or the configuration. The difference is a result of how AMPS is engineered. AMPS was designed to achieve peak performance and scale on modern multi-core hardware. The software architecture consists of a super-pipelined processing engine that allows maximum concurrency to leverage every ounce of CPU to complete tasks. The core engine has been thoroughly NUMA optimized to ensure low jitter and effective use of memory bandwidth. Finally, the entire system has been coded with exacting attention to detail: every data structure, every cache line, every thread, every algorithm, every point where threads interact has been carefully considered to produce a finely tuned processing engine. The result is a system built for “forward scaling” and as new processors, memory technologies, storage devices, and networking devices come to market, the performance delta between RabbitMQ and AMPS will continue to increase. The differences don’t stop at performance. The feature rich queues are a story unto themselves.
Message Queues Reinvented

AMPS takes a completely different approach to message queuing than RabbitMQ. With AMPS queues, all messages are recorded into the AMPS transaction log, a durable, high-performance, fully-queryable sequential message store engineered to support applications that require sustained throughput of millions of messages a second. However, a queue is only one of the ways the AMPS engine can distribute a message. In effect, each queue is an independent view of the messages within the AMPS transaction log. As messages are delivered and consumed, AMPS simply tracks the state of that message in the view. The producer of a message needs no knowledge of either the distribution model or the consumer of the message. New queues, new consumers, and new applications can easily be added with no changes to the producer.
In addition to blazing-fast performance, AMPS provides other benefits:
Ultimate Routing Flexibility AMPS provides the ultimate flexibility in decoupling producers from consumers. The full power of AMPS topic-matching (including regular expressions in the topic) and content-filtering (a combination of XPath and SQL-92 which includes regular expressions, calculated expressions, and user-defined functions) is available for message routing. With AMPS queues, applications are no longer limited to topics, routing keys, or matching on simple key/value pairs to determine delivery. AMPS completely decouples publishers from the details of how the queues are arranged or the ways consumers will use messages. In fact, AMPS can populate queues from its transaction log, so messages can later appear in queues that did not exist at the time the message was published providing ultimate routing flexibility.
Multiple Distribution Models AMPS fully supports multiple distribution models, even for the same message. From a single publish, AMPS can provide the message to any number of pub/sub subscriptions, archive it for audit or back testing, aggregate it into a view, replicate it to a disaster recovery site and enqueue the message for distribution to workers in queues across multiple regions. The publisher does not need to know how AMPS or any of the consumers will use the message.
Aggregation and Complex Event Processing AMPS is content-aware and includes a sophisticated aggregation and event processing engine. AMPS allows the user to create a real-time aggregated view of the contents of the queue as messages are added to and consumed from the queue. With AMPS, the user’s view of the messages in the queue isn’t limited to queue depth or consumption rate. Aggregation provides true insight: for example, a monitoring application can track the total value of orders in the queue automatically, in real-time, and bring your key business metrics and risk into focus.
High-Performance Delivery and Fairness Models Message distribution in AMPS is optimized for high performance and processing efficiency. Traditional queues require consumers to poll the queue periodically, which adds latency and network overhead. AMPS works on a subscription model that provides messages to a consumer as soon as the message is available.
Consumers can declare a backlog, which sets the maximum number of unacknowledged messages provided to a consumer at a given time. In addition, consumers can concurrently acknowledge and process messages. This smart pipelining allows the consumer to run at full capacity without blocking to wait for the next message from the queue.
Delivery fairness models allow the user to tune each individual queue for lowest overall latency, equal balance across processors, or most efficient use of client resources. Fairness is applied across all consumers for each message, and AMPS manages the consumer backlog according to the queue fairness model. Unlike systems that allow a consumer that requests a large batch size to starve other processors, AMPS distributes each message according to the fairness model. This helps ensure that work reaches each consumer, and prevents a single “greedy” consumer from consuming all of the available messages, thus slowing down the overall message processing system.
Many existing queuing products present an interface that is similar to AMPS by polling in a background thread and allowing a client to retrieve multiple messages at the same time. AMPS provides the programming advantages of that model, while solving the underlying problems in a unique way that provides dramatically better performance.
Distributed Queuing and High Availability The AMPS high-availability features fully support distributed queueing using AMPS replication. Replication in AMPS is fault-tolerant and resilient even over WAN connections or if one of the instances is restarted. AMPS uses a unique, patent-pending method to manage message distribution and distributed queueing without partitioning. AMPS instances automatically use remote instances to absorb processing load when processing on a local instance is unable to keep up with the rate at which messages are enqueued. If a replicated instance goes offline and comes back online, AMPS replication automatically synchronizes messages between that instance and its replication peers. With AMPS, there’s no need to trade-off between highly-scalable and highly-available. AMPS provides both in the same deployment.
Content-Based Entitlement Control The AMPS entitlement system is built from the ground up to be content-aware, for precise control over entitlements. The entitlement system provides the ability to grant permissions to both publishers and subscribers based both on the topic and the content of the message, using the full power of AMPS expressions (including custom functions) to specify the content to which a producer or consumer is entitled.
Beyond Queueing
AMPS is built from the ground up to be a complete platform for data-intensive applications that demand the highest levels of performance and throughput. In addition to message queues, AMPS provides other unique capabilities which make it easy to build high-performance applications:
State of the World Database AMPS state of the world databases provide quick access to the current value of each distinct message on a topic. For pub/sub systems, this capability provides a way for a subscriber to quickly retrieve current values. The state of the world database provides full query capability, and also offers optional key/value index for retrieval times that meet or exceed popular NoSQL key/value store databases. AMPS also provides the ability to atomically retrieve current state and enter a subscription for updates, ensuring no duplication or message loss.
Message Recording and Replay As mentioned earlier, the AMPS transaction log is fully queryable. Applications can start a subscription from any point in the transaction log. AMPS replays messages from the log, in the original order. Once replay is complete, the subscriber receives any new messages that arrive. AMPS allows subscribers to pause and resume replay, as well as set a maximum rate for the replay.
AMPS provides even more advanced features such as Out of Focus notifications for detecting when a message is no longer relevant, incremental (delta) updates to messages, and more.
If you’re ready to explore the diverse features of the fastest messaging product, please try an evaluation of AMPS, available from http://www.crankuptheamps.com/evaluate.
60East provides the full details of the test and the code we used at the github repository at https://github.com/60East/comparison-rabbitmq.
Just to keep things fun, we’ll send a free Version 5.0 T-shirt to the first 50 people that download AMPS 5.0 and email the full version number to support@crankuptheamps.com with their mailing address and shirt size.
[1] As described at https://www.rabbitmq.com/confirms.html, "The RabbitMQ message store persists messages to disk in batches after an interval (a few hundred milliseconds) to minimise the number of fsync(2) calls, or when a queue is idle. This means that under a constant load, latency for basic.ack can reach a few hundred milliseconds." Further, applications must be aware of this. After a restart or failover, when consuming messages from a durable queue "... the client could reasonably assume that the message will be delivered again. This is not the case: the restart has caused the broker to lose the message. In order to guarantee persistence, a client should use confirms."
Copyright © 2016 All rights reserved. 60East, AMPS, and Advanced Message Processing System are trademarks of 60East Technologies, Inc. RabbitMQ is a trademark of Pivotal Software, Inc. All other trademarks are the property of their respective owners.